I was given the task of implementing AI Security in my organization. First I thought, AI security should be simple, will perform threat modeling, find some gaps, implement mitigations and that’s it. But that was my mistake. AI Security is more than that. I had the realization that data on which model is trained should be secure as well. I was only thinking about the system but underlying components like data, model, backend, MCP layer, Front end layer all needs to be protected. I had the realization of my life and it was a really tough work.
After that when I understood the entire system in detail and segregated the agentic, non-agentic systems components. Then I was able to perform the AI security in true sense. I identified the sources from where the data was used to train model, where model files were placed, whether those were encrypted or not, were we auditing the various versions of the models, application security testing of the AI system (SAST, SCA, IAC, DAST), MLSecOps consideration and many more checks.
WHY AI SECURITY IS DIFFERENT FROM TRADITIONAL APP SECURITY
- Traditional security mindset: You secure the code, the infrastructure, the network. The system does what you tell it to do.
- AI security mindset: You secure the code AND the data AND the model behavior. The system does things you didn’t explicitly tell it to do because it learned from data.
- Three examples of where they diverge:
- Prompt injection vs. SQL injection — attacker manipulates input to change behavior, but prompt injection works because the model interprets the malicious input as new instructions (not a data value to process). Traditional WAF rules don’t catch this.
- Model poisoning vs. code injection — traditional security assumes your dependencies are trustworthy once vetted. Model poisoning means a trusted model weights can be subtly corrupted through training data, changing predictions without a single line of “code” changing.
- Data privacy in training vs. data privacy in transit — you can encrypt data in flight and at rest, but if the model memorizes PII from training data, it can leak that PII in outputs even with perfect infrastructure security.
“AI security expands the threat model beyond code and infrastructure into the data and the learned behaviors themselves.”
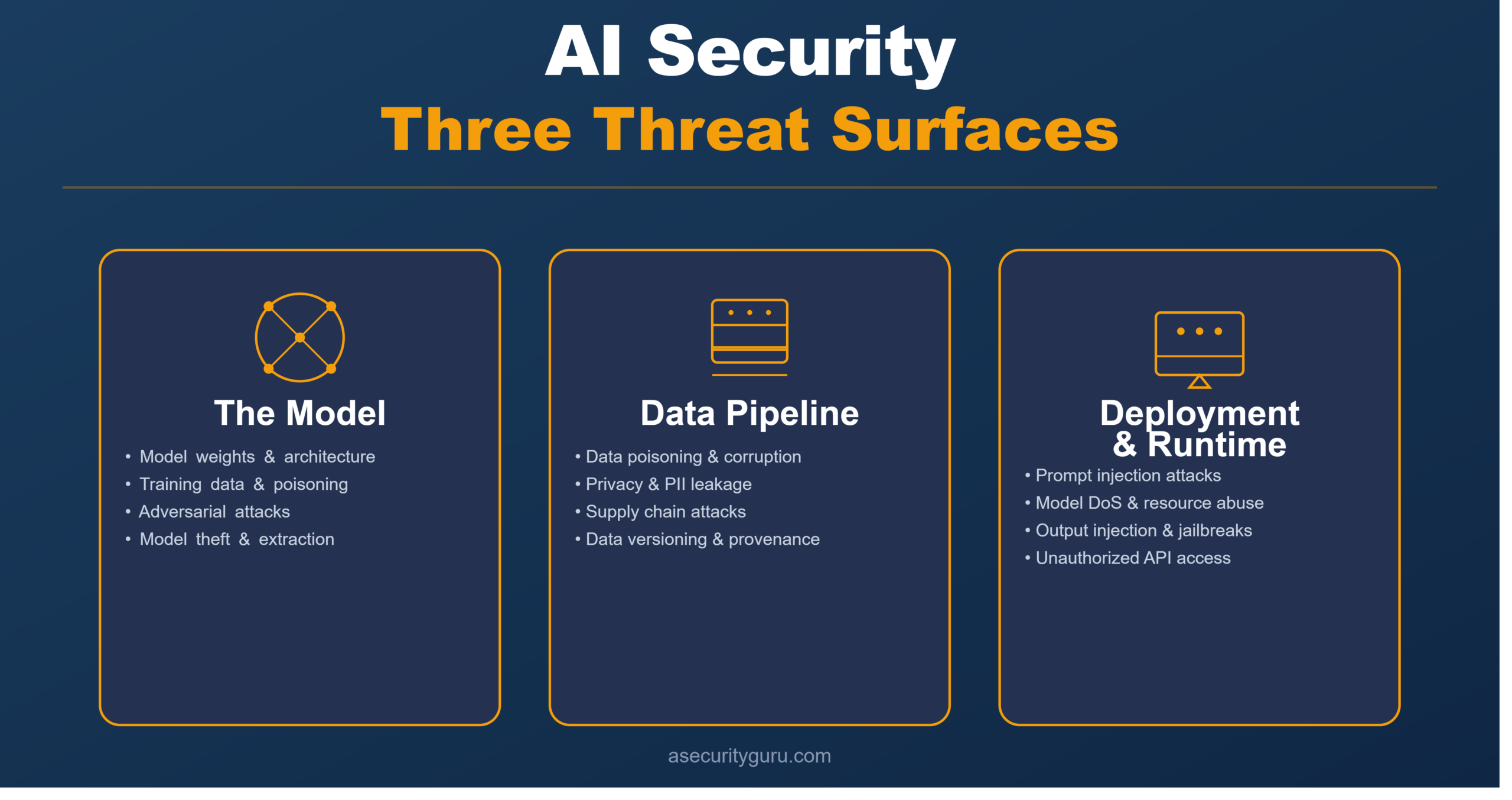
THE THREE CORE THREAT SURFACES IN AI SYSTEMS
1. The Model Itself
- What it includes: weights, architecture, training data, fine-tuning data, hyperparameters
- Key threats:
- Model theft/extraction — attacker queries the model repeatedly to reverse-engineer its behavior or steal weights
- Poisoning/backdoors — attacker corrupts training data to embed a hidden behavior (e.g., “misclassify images with a certain watermark”)
- Adversarial attacks — tiny, imperceptible perturbations to inputs fool the model into misclassifying (e.g., adding noise to an image of a stop sign makes the model read it as “speed limit 45”)
- Existing tools that help: NIST AI RMF (framework, not a scanner), Garak (LLM vulnerability scanner)
- Why traditional AppSec misses this: Code reviews and SAST don’t inspect model weights or training data distributions
2. The Data Pipeline
- What it includes: raw data collection, preprocessing, training data storage, fine-tuning datasets, inference inputs
- Key threats:
- Data poisoning — attacker injects malicious training examples to corrupt model behavior
- Privacy leakage — model memorizes and can reproduce sensitive training data (PII, proprietary business logic)
- Data drift — distribution shift between training and production data causes model degradation (security-relevant if the shift is adversarial)
- Existing tools that help: DVC (data versioning), Delta Lake, CASB tools (for shadow AI data)
- Why traditional AppSec misses this: Most security focuses on code provenance, not data provenance. Where did this training set come from? Who had access to modify it?
3. The Deployment & Runtime
- What it includes: inference APIs, model serving infrastructure (Kubernetes, serverless), integration with downstream systems, monitoring/logging
- Key threats:
- Prompt injection — attacker manipulates user input to make the model execute unintended instructions
- Model denial of service — attacker sends inputs that trigger expensive computations, exhausting resources
- Output injection — attacker tricks the model into generating malicious outputs (e.g., code that gets executed downstream)
- Unauthorized access to inference — attacker calls the model API to extract information or degrade service
- Frameworks that help: OWASP LLM Top 10, input validation frameworks, rate limiting, output filtering
A PRACTICAL STARTING POINT: THE NIST AI RISK MANAGEMENT FRAMEWORK
NIST released the AI Risk Management Framework (AI RMF) in late 2023, updated in 2024/2025
- It’s not a compliance mandate (yet), but it’s rapidly becoming the de facto standard for how to think about AI security governance
- Four main functions: Map (understand the AI system’s context and intended use), Measure (assess risks), Manage (implement controls), Monitor (track performance and drift)
- For an engineer just starting out: Focus on Measure and Manage:
- Measure: Use NIST’s AI RMF workbook to identify which threat surfaces apply to your model
- Manage: For each threat, pick one control from the RMF guidance and implement it (e.g., “input validation” for prompt injection, “data versioning” for poisoning)
- NIST AI RMF is free at NIST official website.
It is very important to map AI vulnerabilities with Risks. I have seen teams categorizing AI vulnerabilities as Critical, High but there is no real organizational risks associated with these and it does not make sense at all.
If you’re serious about AI security, the next step is learning the specific attack patterns that NIST and OWASP document:
- “10 AI Security Skills Every Engineer Needs in 2026” — it covers prompt injection, adversarial ML, MITRE ATLAS, and supply chain security in depth
- For the latest CVEs affecting AI frameworks and models, check CVE Tracker
FAQs
- “Is AI security the same as machine learning security?”
- Not quite. ML security is very specific (focused on protecting the model itself). AI security has broader scope – it includes the entire system: data, model, AI system architecture, its deployment etc.
- “Do I need to learn about AI security if I’m just a DevSecOps engineer?”
- Yes. As a DevSecOps Engineer you need to learn about Model security, Data security, MCP security. But you now need to understand why a Trivy scan on an LLM base image matters differently than on a traditional app (supply chain attacks can poison model dependencies).
- “What’s the difference between prompt injection and a traditional injection attack?”
- Traditional injection (SQL, command, code injection) exploits the system components or execute malicious instructions on the system. Prompt injection exploits the learning of the model — the attacker gives the model new instructions, and the model treats them as legitimate because it was trained to follow natural language instructions.
- “Can traditional WAFs (Web Application Firewalls) protect against AI threats?”
- Traditional WAFs catch some attacks (malicious input structure). But they don’t understand semantics — they can’t tell if your input is trying to change the model’s behavior through social engineering (jailbreaking). Specialized LLM security tools or application-level validation are needed.
- “Where do I find information about AI-related CVEs?”
- Check your favorite CVE tracker (like ASecurityGuru’s CVE Tracker), but also follow security research from AI labs (OpenAI, Anthropic, Google DeepMind security teams) and OWASP’s LLM project for newly discovered vulnerabilities specific to language models.
- “What’s the difference between AI security and ‘prompt engineering’?”
- Prompt engineering is about making the model work better for your use case. AI security is about preventing the model from doing things outside the guard rails. They’re separate (but both important).
NEXT STEPS
Now that you understand the threat surfaces, the next step is hands-on practice. Your two paths:
- Technical deep-dive: Enroll in “AI Security Engineer Bootcamp” on Udemy — covers prompt injection testing, adversarial ML, supply chain security, and building secure AI pipelines with SAST, container scanning, and monitoring.
- Keep reading: “10 AI Security Skills Every Engineer Needs in 2026” for specific, actionable skills (prompt injection defense, MITRE ATLAS, governance frameworks, etc.).
For the latest AI-related CVEs and threat intelligence, bookmark CVE Tracker and check it weekly — AI framework vulnerabilities are being discovered regularly.
ABOUT THE AUTHOR
Raghu the Security Expert has 20 years of experience in Security, DevSecOps, AI Security, and Penetration Testing. He has helped 80,000+ students upskill themselves in DevSecOps, Application Security, and AI Security. Follow his work on LinkedIn, YouTube, and Udemy.